Parallel Programming With OpenMP
- James Burke
- Nov 2, 2020
- 3 min read

In this post, I show an example of reviewing code and making it run faster, with an analysis of the results in a graph at the bottom of this post.
What is OpenMP?
Short for 'Open specification for Multi-Processing', OpenMP is a standard API for defining multi-threaded shared memory programs. It is an explicit programming model, offering programmers full, manual control over parallelisation.
Which program is being reviewed?
I'll be using the open source C++ cosinekitty raytrace program [link]
Where do we start?
We can start anywhere, but typically start with the most expensive functions. This program comes with sample renders included, one being of a chessboard:

Firstly, we identify an expensive function: when, in the command prompt, you enter the command to render this image, it calls a certain function from the main source file. Each render has their own respective function. In this function we can see that there is a call to another function which one would identify as being the most expensive- the function which is responsible for generating the image, pixel by pixel, determining the right colours through ray tracing. Very time-consuming indeed. From this, we navigate to the function ('Scene::SaveImage' within 'scene.cpp').
Secondly, we identify an area of the function which can benefit from being parallised. This will be a part of the code where there are a bunch of repetetive tasks which can be divided amongst multiple threads. This function will see plenty of repetition, as it is responsible for generating each pixel of the image which, as one would expect, would take longer if the dimentions were increased for a higher overall pixel count, or the antialiasing factor increase too. Each of which are parameters which are passed to this function. This for loop enscapsulates the bulk of the work, being responsible for ray tracing specifically:
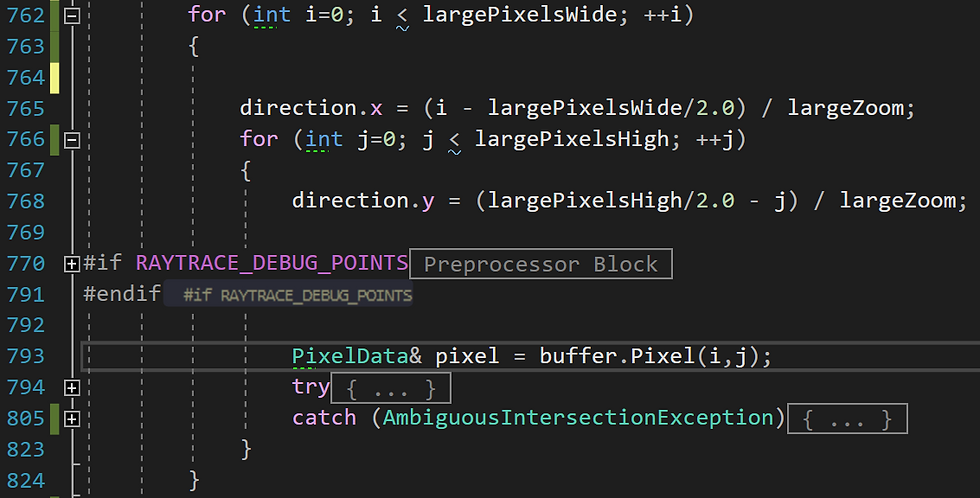
We would want to parallelise from the top-most loop, so we must introduce this OpenMP constructor right above line 762:
#pragma omp parallel for This specifies a parallel region, specifically spanning the following loop, from which the master thread will split into however many threads possible (which makes a 'team' of threads') based on the workload and availability of threads on the specific hardware. Optionally, just at the end of this, you can add this clause to specify how many threads should be in the team:
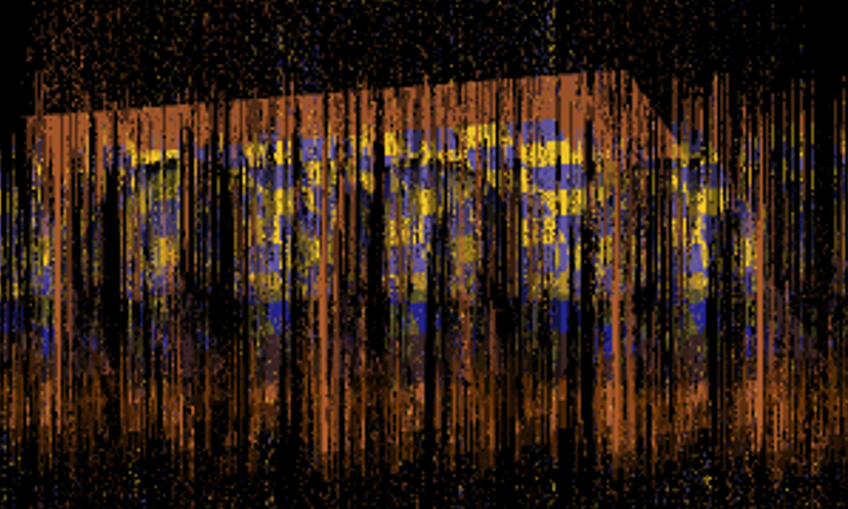
#pragma omp parallel for num_threads(16)But wait! There is more to this than writing a constructor to specify a region. In multithreading, we often come across the problem of race conditions, which occur when multiple threads try to change the same data at the same time- this naturally happens in a shared memory model. Problems arise when one thread is working on a piece of data which may suddenly be corrupted due to the actions of a different thread. In this context, race conditions can produce an image like this:
To parallelise a loop, you must make each loop iteration independent, allowing each respective loop to execute safely in any order. This is achieved through removing loop-carried dependencies, i.e. through localisation of global variables. The declaration of the vector 'direction' comes from outside the loop (it's declared shortly before the loop starts), but it is used in the loop and its nested loop. Let's localise this to make each iteration run independently:

With that done, we move on through the loop where we see a function call to 'Scene::TraceRay'. Within this function, near the beginning, there is a call to 'Scene::FindClosestIntersection'. In this function there is need for localisation, so the variable on line 656 is commented out, and declared a local variable on line 655:

After this, I navigate to the declaration of this function (which brings me to a header file), and do the same, to localise the list:

In this file, with the magic of CTRL + F, I search for each occurence of this variable to make sure global instances of it are commented out. With this done, I comment out the contents within the catch statement in the nested loop from the beginning, as they are no longer necessary and are hazards for race conditions.
Measuring time
Before the loop:
double start_wtime, end_wtime;
start_wtime = omp_get_wtime();After the loop:
end_wtime = omp_get_wtime();
printf("Work took %f seconds\n", end_wtime - start_wtime);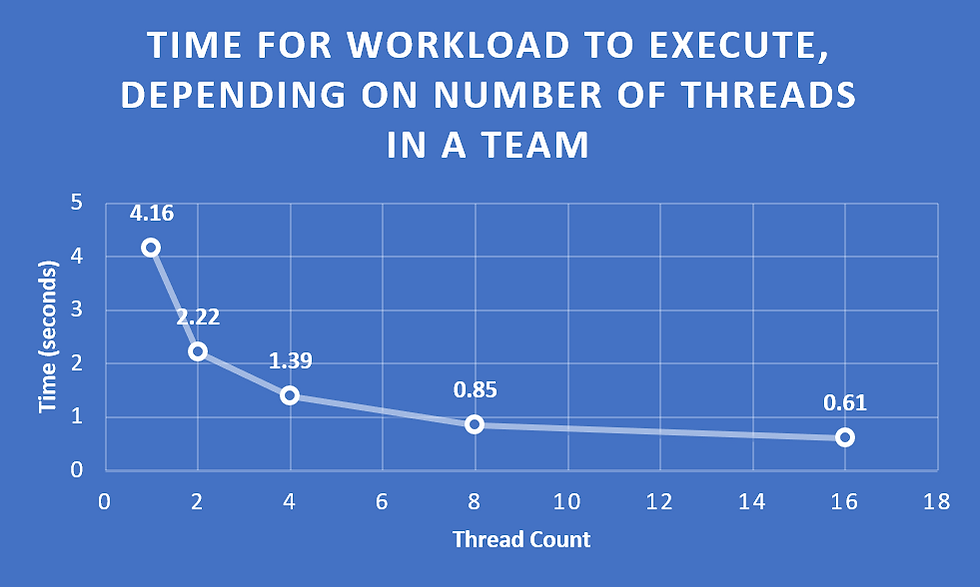
I had taken measurements by changing the parameter of the clause which specifies the number of threads in a team. These were tested for 1, 2, 4, 8 and 16 threads (the maximum of my CPU). As thread count increases in the team, time for completion of this workload is reduced, initially seeing a sharp decline which gradually plateaus. With each increase in thread count, the effect becomes less pronounced. Reasons for this may include coordination/synchronisation, or be related to load balancing. These will be explored more in a future post.


Comments